
Technique SEO
Comme son nom l’indique, le robots.txt est un fichier qui s’adresse avant tout aux robots (appelés également bots ou spiders) qui parcourent le web. Indispensable en SEO, il permet de donner des instructions à ces robots, en particuliers ceux des moteurs de recherche comme Google et Bing. A travers ce guide, vous allez apprendre à lire et comprendre les règles qui sont données dans le robots txt, et également à bien le configurer pour l’adapter au mieux aux spécificités de votre site internet.

Qu’est-ce que le fichier robots txt ?
Le robots.txt est un simple fichier texte, placé à la racine d’un site internet, et qui a pour vocation de donner des instructions aux robots des moteurs de recherche. Il permet principalement d’autoriser ou d’interdire l’exploration d’une zone (répertoire, sous-répertoire, page unique…) ou d’un type de fichier (.pdf, .css, images, etc) présents sur votre site web. Le fichier robots.txt est donc le support qui permet de mettre en oeuvre ce qu’on nomme le protocole d’exclusion des robots.
Concrètement dans le cadre de votre stratégie de référencement naturel, vous allez pouvoir utiliser ce fichier pour interdire à Google d’aller consulter le contenu d’une page ou d’un dossier que vous considérez comme non pertinent pour lui.
Prudence cependant, un mauvais réglage dans le fichier robots.txt peut avoir des conséquences lourdes sur votre SEO, par exemple si vous interdisez à Google et aux autres moteurs de recherche d’explorer certaines URL importantes. En cas de doute, mieux vaut s’abstenir plutôt que de prendre le risque mettre en place des directives néfastes à votre SEO.
Attention à ne pas confondre “exploration” et “indexation” en SEO. Le fichier robots.txt sert à interdire l’exploration (le crawl d’un répertoire, d’une page, d’un document…) mais il n’a pas pour vocation d’interdire l’indexation. Une page bloquée via votre robots.txt peut très bien être présente dans l’index de Google, si a été indexée avant la mise en place du blocage par exemple.
Pour désindexer une page, on privilégiera plutôt la balise meta robots noindex, placée dans l’entête de notre document : <meta name= »robots » content= »noindex »>
Comment créer un fichier robots.txt pour son site internet ?
Créer le robots.txt est quelque chose d’assez simple. Tout ce dont vous avez besoin est un simple éditeur de texte, tel que le bloc note de Windows. Il faudra simplement vous assurer que le nom du fichier soit bien écrit en minuscule, comme ceci : robots.txt
Les noms comportant une ou des majuscules tels que ROBOTS.TXT ou Robots.txt sont interdits.
Il vous faudra ensuite placer le fichier sur votre serveur, à la racine du site, via votre client FTP habituel.
Pour vérifier si un fichier robots.txt est déjà présent sur votre site, il vous suffit de taper son nom dans la barre d’adresse de votre navigateur, à la suite de la racine de votre nom de domaine.
Par exemple, pour le domaine www.orixa-media.com, le robots txt est situé ici : https://www.orixa-media.com/robots.txt
Par convention, ce fichier doit toujours être placé à la racine. Si vous le placez ailleurs, alors les moteurs de recherche ne pourront pas prendre en compte les instructions qui s’y trouvent.
A noter : de nos jours, le fichier robots.txt est généré automatiquement par la plupart des principaux CMS.
Les commandes du robots.txt
Autoriser le crawl de l’ensemble du site sans aucune restriction
User-agent: * Disallow:
La commande User-agent: * permet d’indiquer que les règles situées en dessous s’adresse à l’ensemble des robots.
La seconde ligne Disallow: indique que l’accès n’est restreint pour aucun document.
Interdire le crawl de l’ensemble du site pour les robots
User-agent:* Disallow: /
La commande Disallow: / indique aux robots qu’ils ne peuvent accéder à aucune page sur l’ensemble du site.
Une telle directive ne doit être utilisée que dans des cas très particuliers, afin de ne pas nuire à votre référencement naturel (en cas de travail sur un environnement de pré-production par exemple).
Interdire le crawl d’un répertoire ou d’un sous sous-répertoire
User-agent:* Disallow: /repertoire-1/ Disallow: /repertoire-2/sous-repertoire-a/
Ces commandes indiquent à l’ensemble des robots de ne pas explorer le répertoire n°1, ainsi que le sous-répertoire A, présent dans le répertoire n°2
Interdire le crawl d’une URL en particulier
User-agent:* Disallow: /page-1.html
Ici on interdit à tous les robots d’aller consulter le document intitulé page-1.html
Autoriser le crawl d’une URL située dans un répertoire interdit
User-agent:* Disallow: /repertoire-3/ Allow: : /repertoire-3/page-1.html
Ici, l’ensemble du dossier n°3 est bloqué par la ligne Disallow, cependant en créant une exception avec la commande Allow, Google et les autres moteurs de recherche pourront quand même consulter et indexer le document intitulé page-1.html
Interdire le crawl pour un robot en particulier
User-agent: Googlebot Disallow: /repertoire-a/
La commande User-agent: Googlebot permet de signifier que les règles suivantes ne vont concerner que Googlebot, et non pas les autres robots.
L’instruction Disallow: /repertoire-a/ permet quand à elle d’interdire le crawl du dossier mentionné.
Indiquer l’emplacement de son fichier sitemap.xml
User-agent: * Sitemap: https://www.orixa-media.com/sitemap.xml
En plus des commandes Allow et Disallow, il est également possible d’utiliser le fichier robots.txt pour renseigner l’emplacement de son fichier sitemap xml aux moteurs de recherche.
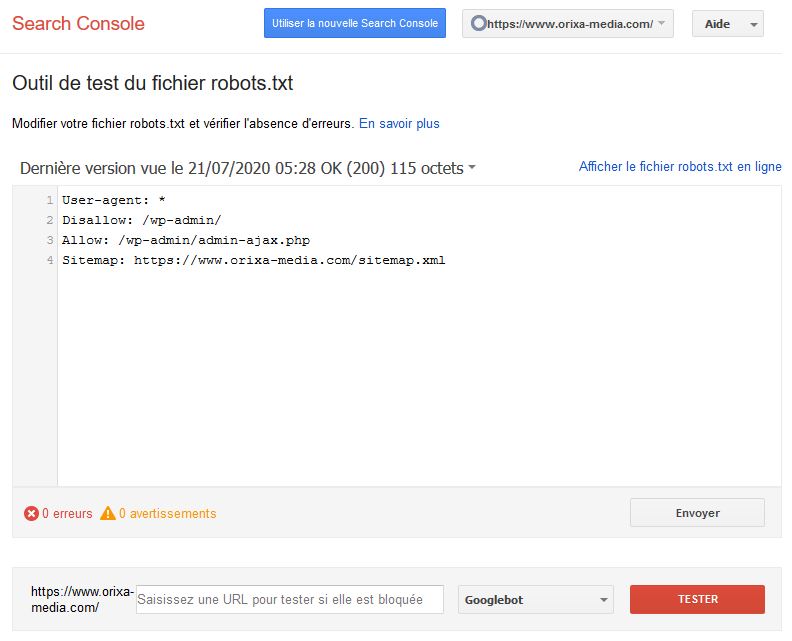
Tester le bon fonctionnement de son fichier robots.txt à l’aide de la Search Console
Vous venez de mettre en place de nouvelles directives dans votre fichier robots.txt et vous aimeriez vérifier qu’elles ne comportent pas d’erreur de syntaxe ? Ou vous souhaitez simplement savoir si une URL est bloquée ou non par les règles contenues dans votre fichier ? Grâce à la Google Search Console, vous allez pouvoir tester et contrôler le bon fonctionnement de votre robots txt.
En cas d’erreurs, une croix rouge vous signale la ligne concernée.
Pour vérifier qu’une page est bien bloquée (ou accessible) renseigner simplement son URL relative dans la ligne du bas. Si l’accès à la ressource est interdit, l’outil vous indique alors la ligne qui en est à l’origine.
Vous savez désormais comment utiliser votre fichier robots.txt pour restreindre l’accès des robots à certains documents sensibles de votre site internet. Vous avez des doutes sur la configuration de votre robots.txt et souhaitez réaliser un audit technique complet ? N’hésitez pas à prendre contact avec notre agence SEO pour obtenir votre devis personnalisé.